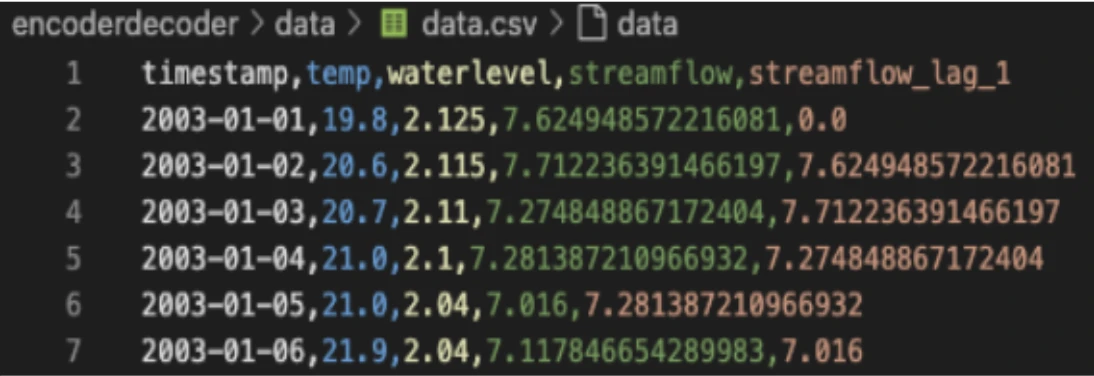
i discuss my college project on using deep learning (notably, transformers’ flavours) for prediction of streamflow of river stream (here, hemavathi basin).
the project involves rainfall, river streamflow & temperature data for the study area: hemavathi basin, kaveri river, karnataka, india.
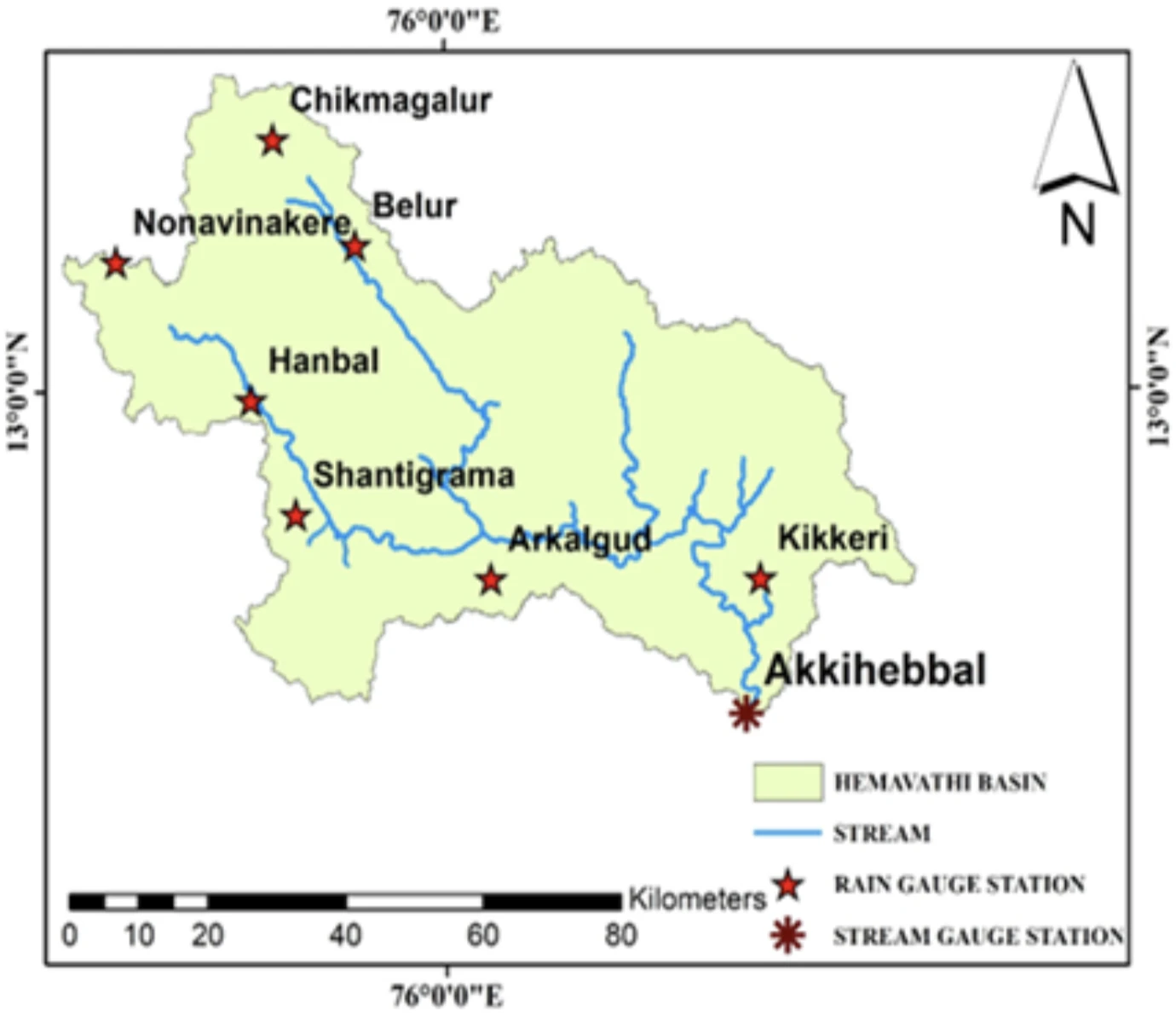 thanks to phd senior
thanks to phd senior mukul sahu for arranging the data from India Metrological Department (IMD). The data consisted of daily data points from 2003-2020 with a total of 6575 rows each.
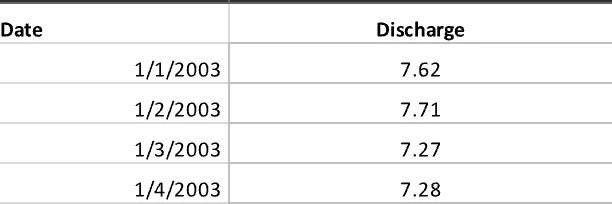
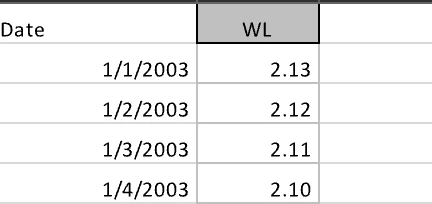
mostly traditional machine/deep learning techniques are used in this niche space of hydrology. he had some experience with Lstm & Cnn but i proposed that attention based transformers shall be explored and i started working on it. my friend nihal badiger trained xgboost & Lstm models. i was exploring on how to best make timeseries data work with transformers. the work includes around 1month of worktime, and may see more progress before its published.
as a result, this page will probably be updated in the future.
the intuition is to use timestamps as positional encodings as its used in language modelling. i built encoder-decoder vanilla transformer and also use LagLlama which is trained on timeseries with llama architecture. I also read a chinese paper doing something similar with yangtze river Liu et al., 2022 where they modify the transformer architecture to fit their data, we had different data than them though. Another interesting paper which introduces spacetimeformer concept of spatio-temporal transformers for multivariate timeseries data (yet to be tested for this project)
- vanilla encoder-decoder based model
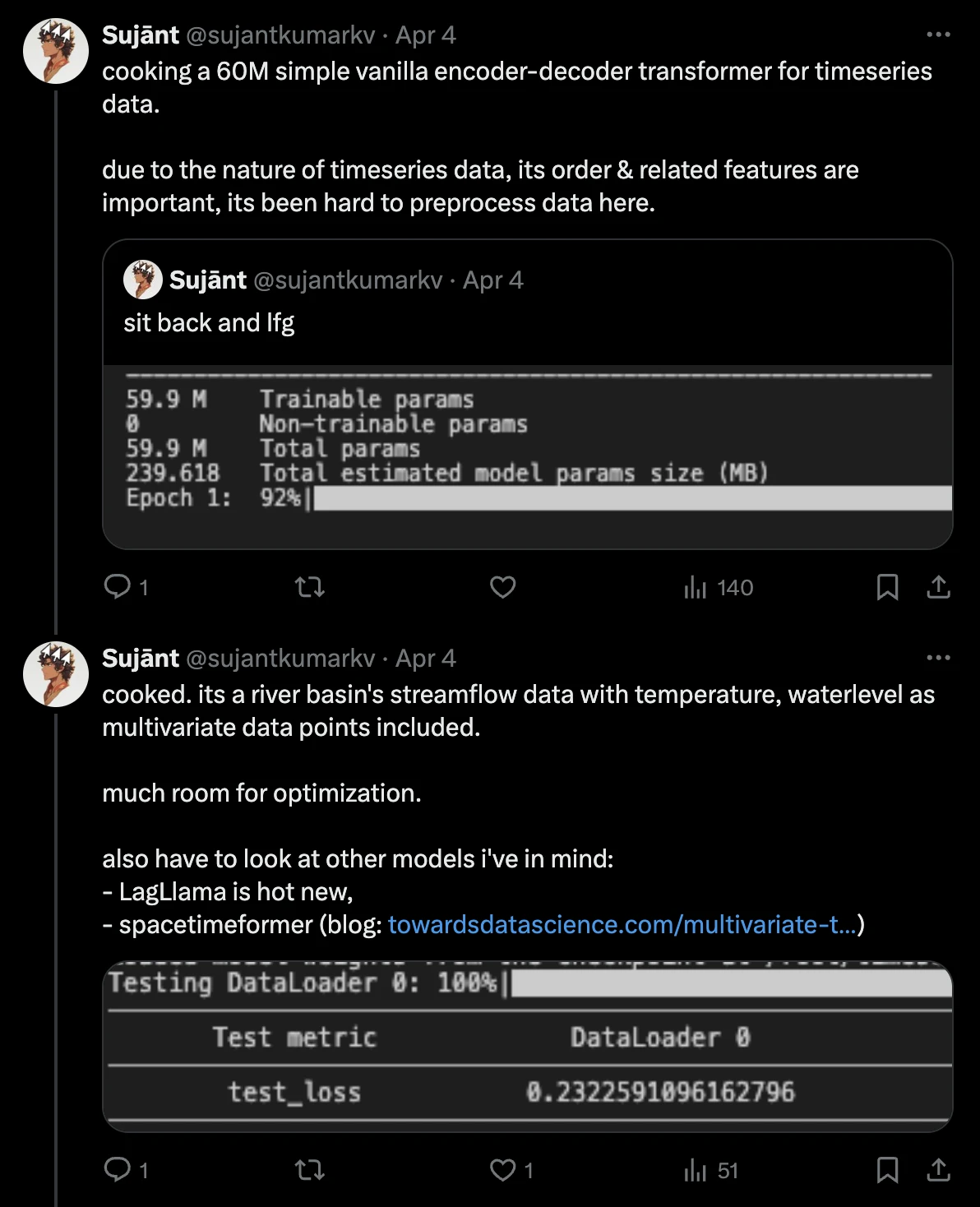
It’s a ~60M parameter model trained on 10 epochs over the multivariate data of average temperature, waterlevel, streamflow & a generated lag feature: streamflow_lag_1. find relevant code, here.
overview of the model, model configurations and validation scores.
the biggest pain i had to bear was digging deep into gluonts libary by amazon which is used for data processing & handling in both examples.
the huggingface example blog consists of a decoder-only model with a probablistic head & uses monash_tsf dataset for timeseries which was very confusing as to what does the data points represent & in which order.
- latest foundation model called
LagLlama, based on the Llama architecture from Meta but trained specifically on huge amounts of time-series data which has been used with zero-shot and fine-tuned upon our datasets to further improve the quality of results.
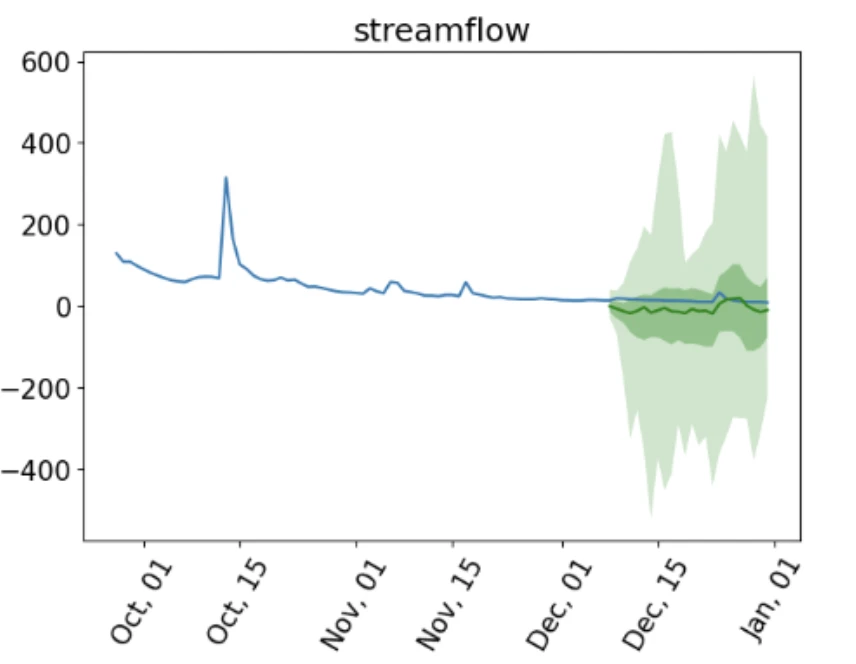
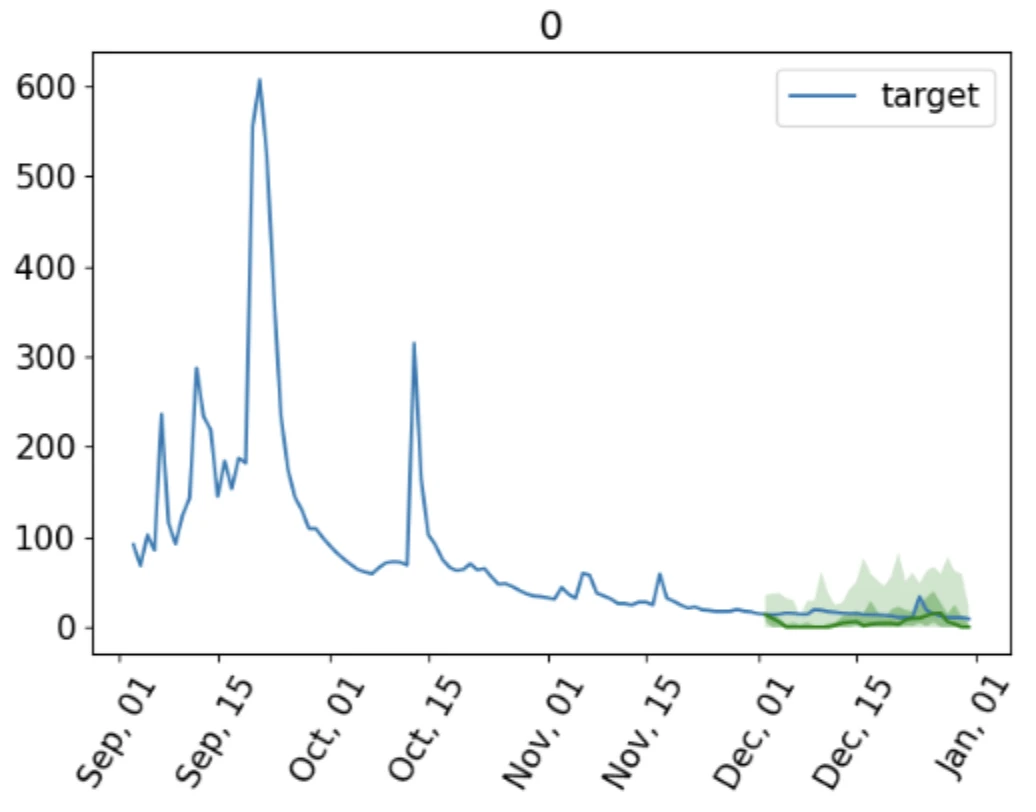
here’s the zeroshot discharge/streamflow predictions, it does impressively well for its size:
Further, we finetune the 2.4M parameter lagllama model.
I trained it for 50 epochs on a Nvidia T4 GPU freely available in google colab & other online services like lightning studios.
here’s lagllama github repo. it contains more details & notebooks released by the team.
lagllama.
what’s next: more updates may involve testing: amazon’s cronos model, timegpt, spacetimeformer (spatio-temporal), decoder-only transformer.