the power and usecases of LLMs were evident when i used them. my friend and i were discussing legal arbitration issues in india because his dad had to oversee & help with documents for a few cases. it was clear that legal being the most text intensive text-in text-out business could leverage LLMs. so in mid-2023, i started skipping classes in learning all the ways to make this happen. also participated in buildspace to keep track & ship faster.
 being gpu poor, i can’t randomly test a bunch of hypothesis on models, i need to understand it really well and also its possible errors beforehand so as to not burn gpu dollars. i put extra time to read post-training reports, blogs etc. i dived deep into transformers and wanted to conquer it to each matmul also because i wanted to understand what would be the best solution to what i’m building. i loved gpt4 responses while brainstorming together.
being gpu poor, i can’t randomly test a bunch of hypothesis on models, i need to understand it really well and also its possible errors beforehand so as to not burn gpu dollars. i put extra time to read post-training reports, blogs etc. i dived deep into transformers and wanted to conquer it to each matmul also because i wanted to understand what would be the best solution to what i’m building. i loved gpt4 responses while brainstorming together.

LLMs hallucinate & as karpathy puts it that its not a bug, but a feature but the legal world needs aboslute certainity, not just the law but its interpretation changes how its carried out, so each word, grammar, named entity recoginition etc of past cases and much more, i was looking for the best embedding models, finetuning its layers to get better embeddings as a result, reading research on it and so on.
i decided to go ahead with taking a llama2-7b, finetune it which shall supposedly give me good quality embeddings from initial model layers which i can use it for semantic or semantic+normal (hybrid) search to find retrieve similar cases and then use another llama2-70b (finetuned on indian law knowledge) to get final results via retrieval augmented generation or RAG.
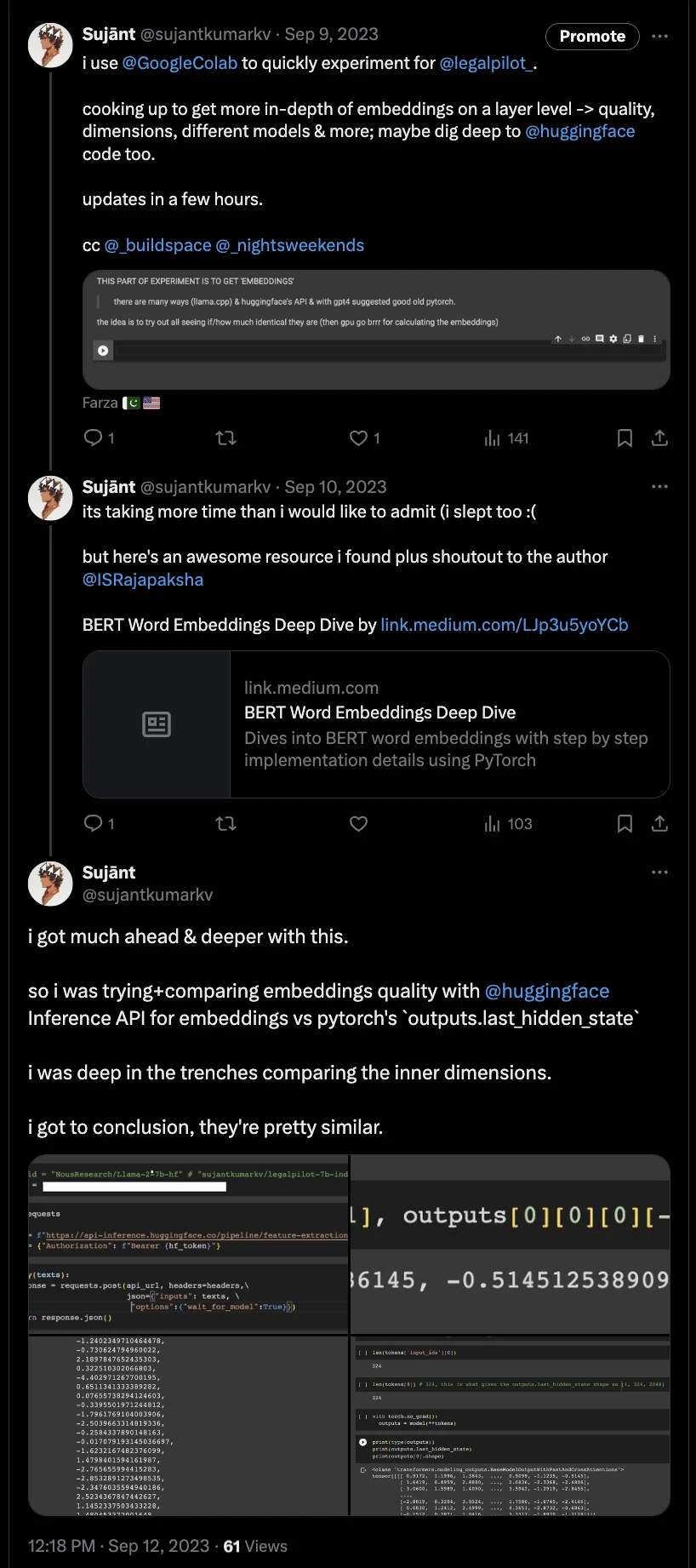
i was confused as if the initial decoder only llama2’s embeddings were how much similar or different to other embedding only models or those that were spit out from llama.cpp’s './embedding' command, am i even doing it correct or which would be better quality?
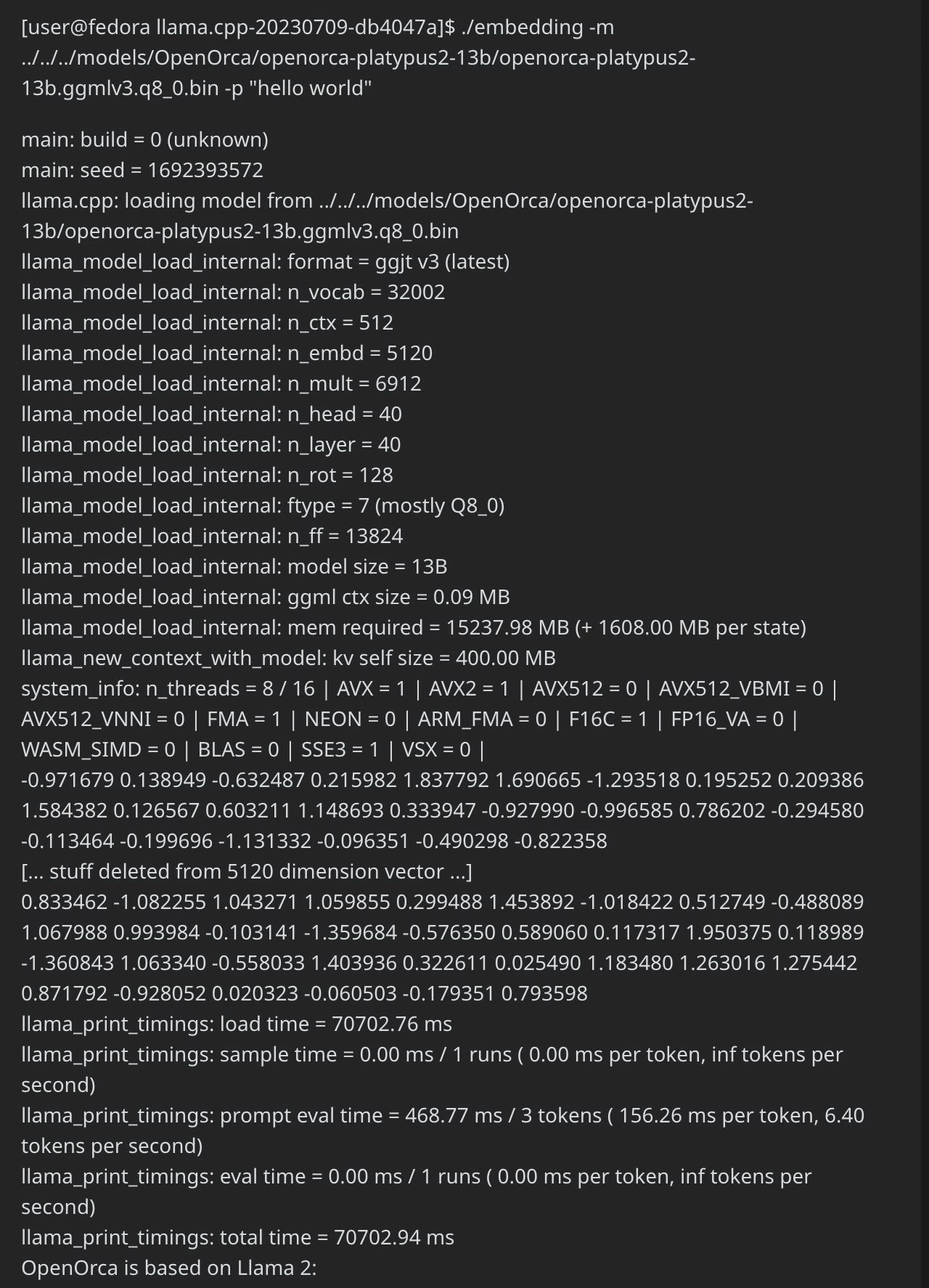 again being gpu poor, so i dug in lot deeper into huggingface codebase to see how they exactly give out embeddings, also tried their APIs.
again being gpu poor, so i dug in lot deeper into huggingface codebase to see how they exactly give out embeddings, also tried their APIs.
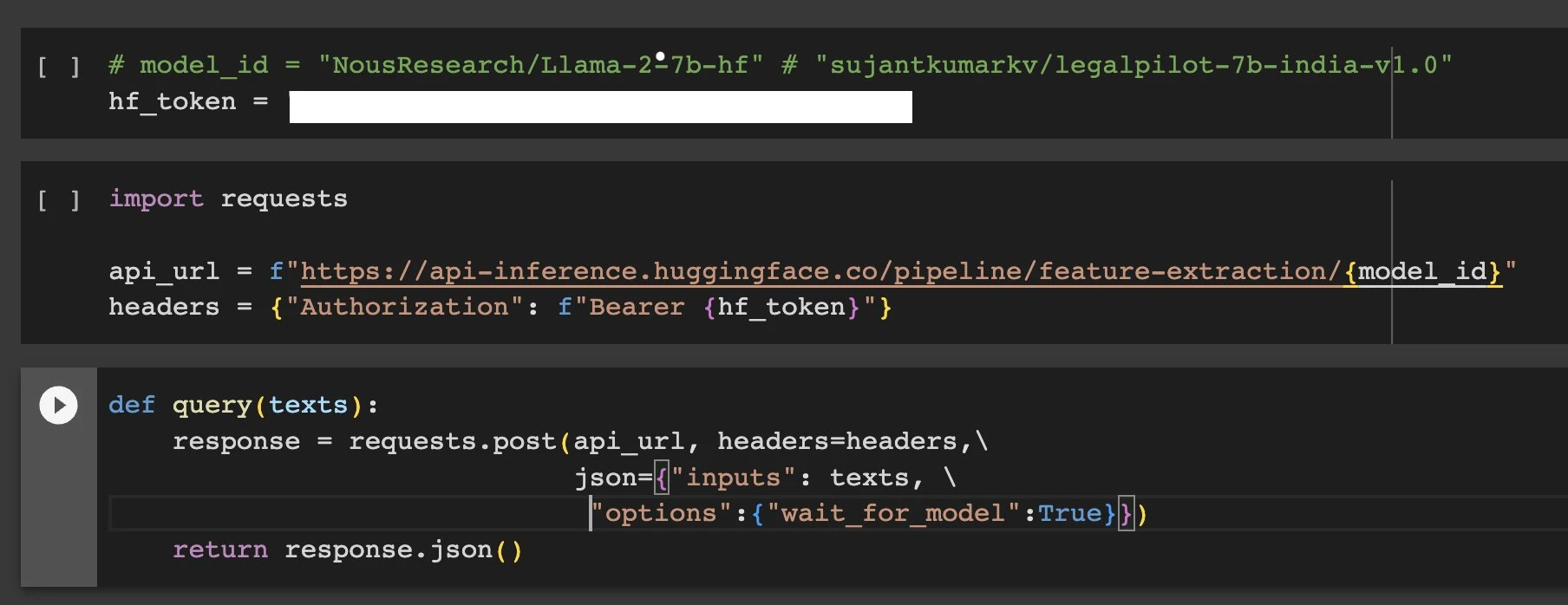 i was also literally comparing their tensor sizes to ensure if they were the same… it was brain fog. it was similar as to what i found though.
i was also literally comparing their tensor sizes to ensure if they were the same… it was brain fog. it was similar as to what i found though.
i also luckily got some openai & msft compute credits from @BuildersTribe, thanks to @web3_ayush. i joined facebook/telegram groups, trying to understand lawyers’ work and issues to build features around them. some cool folks also reached out trying to help.
like with AmitDeshmukh, we discussed on getting it to pass law bar exams to get attract eyes on it. also, with Arvind Sankar.
 he’s a lawyer into tech, he suggested to use a middle model trained to give deterministic outputs, maybe like having a json outupts, that needed to be designed. he explained the bar exam isn’t a good metric & we discussed evals.
he’s a lawyer into tech, he suggested to use a middle model trained to give deterministic outputs, maybe like having a json outupts, that needed to be designed. he explained the bar exam isn’t a good metric & we discussed evals.
now, comes the data part:
80% of the time and pain goes here for those who’re starting out to build new things.
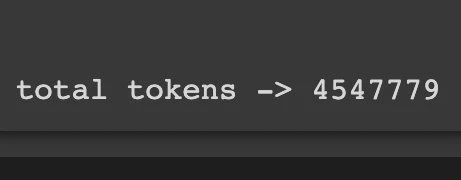
for the first time in my life, i literally paid for pdfs & docs xD for data including indian law & more formatted, cleaning it all up was a pain and literally took a month or so as i went through almost every single pdf, doc and text file. it was a mistake as i was naive, that’s not how you build production datasets, i barely used libraries & tools and that’s partly because the engineer in me likes doing stuff from scratch without dependencies but i was wrong. there were alignment issue of content, images, weird ordering, different formats plus i didn’t know what i’m doing because i didn’t understand which is good data vs bad data in this context, an expert was needed here but i didn’t have the funds to hire atm. though, i finally churned out a total of 4.5M tokens.
i also finetuned gpt3.5 for quick testing, it was working good enough. so i 4bit qlora finetuned a llama2-7b (legalpilot-v1) to use for embeddings & retrieval as mentioned in the approach earlier. the cleaned dataset is a corpus, not instruct-tuned as my intuition was to make it learn more knowledge on the nuances, terms & indian law and not just behave like a chatbot.
 my attempt was to influence its interal embeddings representation to get better results, i was reading some research on that, but honestly, not much progress there. model+datasets can be found, here
my attempt was to influence its interal embeddings representation to get better results, i was reading some research on that, but honestly, not much progress there. model+datasets can be found, here
for the business aspect, my approach was to sell to law firms & not lawyers, so not b2c but b2b. on the technical aspect, my approach was to let law firms have their hosted models on their infra (i would setup if they didn’t have already) because two things: proprietary data which they have is confidential & its the actual vaulable data that matters. my moat would be if i had deals with firms.
i shipped the basic chatgpt interface with my model serving and launched on reddit, reached out and had meetings fixed with some firms. we talked but deals mostly didn’t went through plus i had exams :( i wanted to collect some data on users’ interaction to further instruct-tune the model, i had a few users (free customers not firms yet) but data collection wasn’t much.
eventually, due to no legal expert for data gathering and cleaning, my laziness & no revenue motivation, i slowly stopped working on this, but i’m proud of the meticulous efforts i put in as projects aren’t totally wasted, it surely helped me learn a lot about technical depths plus launching 0 to 1 or maybe i’m just coping who knows? onwards to learn and build more :)